製薬カスタムモデルが伸長‐企業翻訳データで高精度化

武山氏
翻訳センターは、同社が製薬業界向けに提供する機械翻訳「COTOHA Translator 製薬カスタムモデル」の契約数を順調に伸ばしている。定評のある翻訳精度の高さは、モデル開発に参画する製薬企業が拠出する、一般には公開されない医薬品開発文書の翻訳データを中心に学習させていることに由来する。アップデートも約半年に1回と、常に進化を続ける同モデル。現在は、前臨床分野および製造領域であるCMC分野の翻訳精度の向上にも注力している。
製薬カスタムモデルは、製薬企業の多くが医薬品開発文書の作成に多大な時間を費やしているという課題を解決し、業務の効率化、生産性の向上を推し進めるサービスとして開発された。
このモデルの特徴は、同社およびNTTコミュニケーションズ、みらい翻訳という座組みに、サービスを享受する側の製薬企業が参画して開発されたことにある。当初は12社だった参画企業は今や約2倍にまで伸長した。参画企業の構成も国内・外資大手に限らず、日本に進出間もない企業など様々だ。
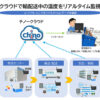
製薬カスタムモデルは、参画企業から収集した翻訳データを独自処理によりコーパス化して機械翻訳にモデル学習させ、そのプラットフォームをNTTコミュニケーションズから各契約企業に提供する形で運用されている。
同モデルの精度の高さは、この一般には公開されない医薬品開発文書に基づき、薬剤、化合物に関する用語、研究開発に関わる文書特有の言い回し、構成からなる翻訳データに由来する。
加えて同社に機械翻訳による訳文を人間の翻訳者が手直しするポスト・エディットを依頼することで、良質な翻訳データがさらに収集・蓄積されていく。そして約半年に1回、同モデルのアップデートを行うことによって、導入時よりさらに訳の質が高まり、進化していく仕組みだ。
製薬カスタムモデルは臨床分野に特化して開発されたモデルであるが、同社は現在、前臨床分野、CMC分野の翻訳精度の向上にも取り組んでいる。各製薬企業での全社的なDX推進による需要増加が理由だという。
同社はセキュリティ面にも細心の注意を払っている。参画企業から翻訳データを受け取る際はクラウドストレージの使用や暗号化などの対策を施している。さらに翻訳データの分析、処理を行う際は顧客名、化合物名、薬剤名などを全てマスキングし、個社の特定につながる情報を秘匿化している。
そして同社は次のステップも見据えている。一つは音声認識による翻訳機能の追加である。例えば海外とのオンライン会議において、相手の話した外国語が日本語の字幕として表示されるといったイメージだ。今後は、参画企業などから希望を募り、実証実験に入る予定だという。
また、昨今話題の生成AIについて、取締役営業統括の武山佳憲氏は「製薬カスタムモデルに生成AIの機能、技術をどのように取り入れることができるのか、事務局を中心に関係企業間で連携を取りながら議論を進めている」と、現状を説明する。データのセキュリティ面、参画する各企業の生成AIに対するポリシー、技術の進展などを慎重に見極めながら進める意向だ。
武山氏は、「生成AIなどの新技術の動向は常に注視しているが、重要なのはそれをいかに活用し、ユーザーの実際の業務に役立てていくかということ。人手の翻訳会社である私たちは、現場の方々の声を常に大切にし、丁寧な対応を積み重ねていくことで、お客様の課題解決に貢献していきたい」と語る。
翻訳センター
https://www.honyakuctr.com/